



The AI chatbot market has been overrun with ChatGPT substitutes ever since ChatGPT’s popularity spiked in November. Choosing which chatbot to utilize might be challenging because they all have different LLMs, prices, user interfaces, internet connectivity, and other features.
The University of California, Berkeley students, and staff that founded the Large Model Systems group (LMYSY Org.), an open research group, developed the Chatbot Arena to simplify comparing them.
The Chatbot Arena is a testing ground for LLMs where users can compare two randomized models by introducing a prompt and choosing the better response without being aware of which LLM is responsible for either response. After selecting a chatbot, users can view which LLMs were used to produce the result.
According to LMSYS Org, the user ratings are utilized to rank the LLMs on a leaderboard using the Elo rating system, which is a popular chess rating system.
When I first tried the arena, I used the request, “Can you write me an email telling my boss that I will be out because I am going on a vacation that was planned months ago.”
One response had considerably more context, length, and fill-in-the-blanks that would have been acceptable for the email, whereas the other was totally different.
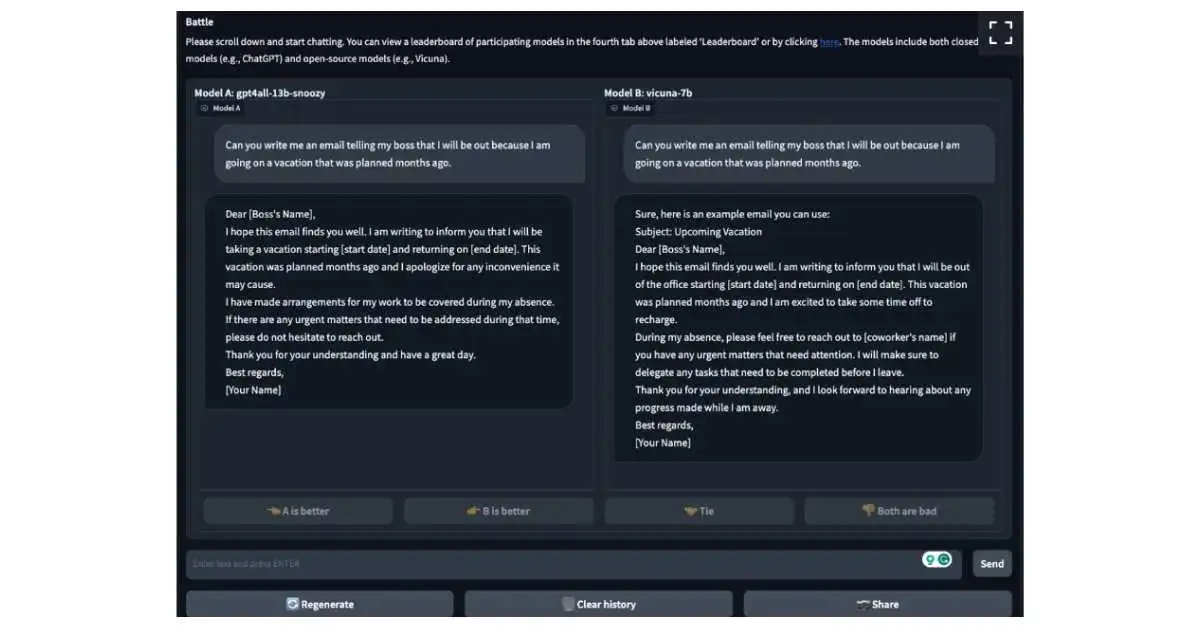
I selected “Model B” as the winner and later learned that it was actually the LLM developed by LMSYS Org based on Meta’s LLaMA model, “vicuna-7b.” “gpt4all-13b-snoozy,” an LLM created by Nomic AI and modified from LLaMA 13B, was the losing LLM.
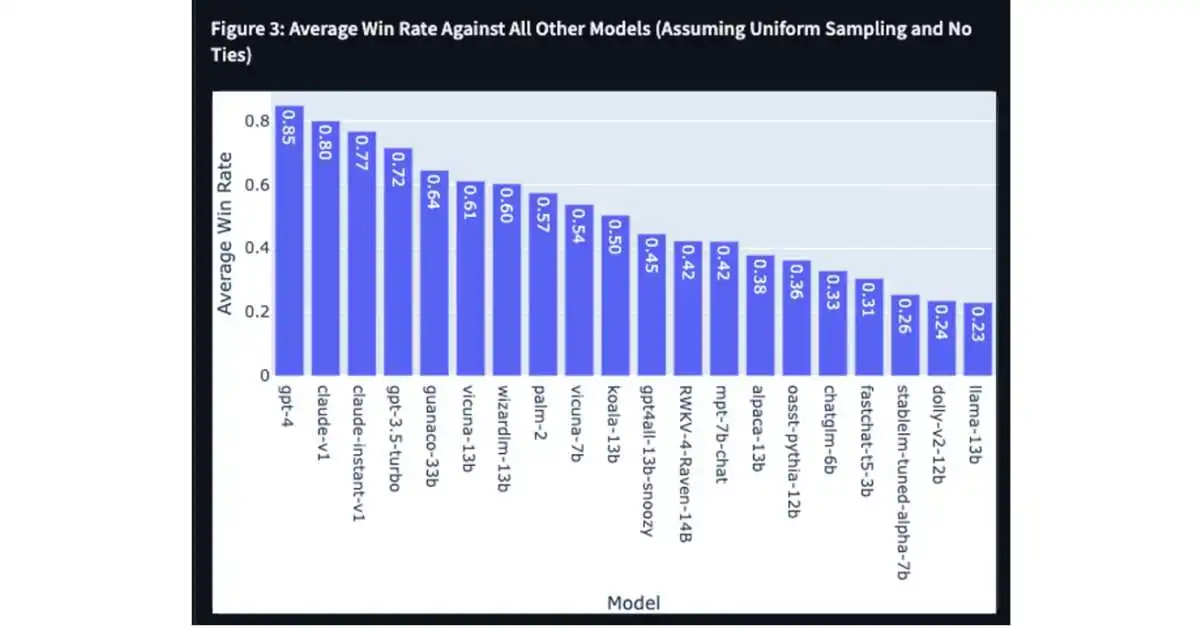
Unsurprisingly, the leaderboards presently rank GPT-4, OpenAI’s most sophisticated LLM, first with an Arena Elo rating of 1227. The LLM created by Anthropic, Claude-v1, is rated second with a score of 1227.
For more information, Check out our recently covered posts about ChatGPT, Google Bard, and Bing Chat
- How To Use Bing Chat? 5 Easy And Simple Steps To Learn It
- ChatGPT and Google Bard Both Generate Free Windows 11 Installation Keys
AI chatbot rankings, GPT-4 is present in both Bing Chat and ChatGPT Plus, making those two chatbots the most accessible. The second-ranking Claude of Anthropic is not yet accessible to the general public. However, there is a queue where users can sign up for early access.
A submodel of PaLM 2, PaLM-Chat-Bison-001, the LLM that comes in second to Google Bard, is ranked eighth in the leaderboard. This ranking is consistent with the popular opinion that Bard is neither the worst nor one of the greatest.
You can choose the two models you want to compare on the Chatbot Arena website. This option might be useful if you wish to test out particular LLMs.
We hope you enjoyed this post! If you did, please bookmark thecurrent-online.com so you can come back for more great content.